KMP Algorithm
KMP Algorithm
What is KMP?
KMP is a string matching algorithm that is used to find a substring in a string. It is an efficient algorithm that has a time complexity of O(n+m) where n is the length of the string and m is the length of the substring.
KMP 是一个解决 模式串在文本串中是否出现过,如果出现过,则最早出现的位置的经典算法。KMP 算法的时间复杂度是 O(n+m)。
For Internal Use:
Leetcode Links
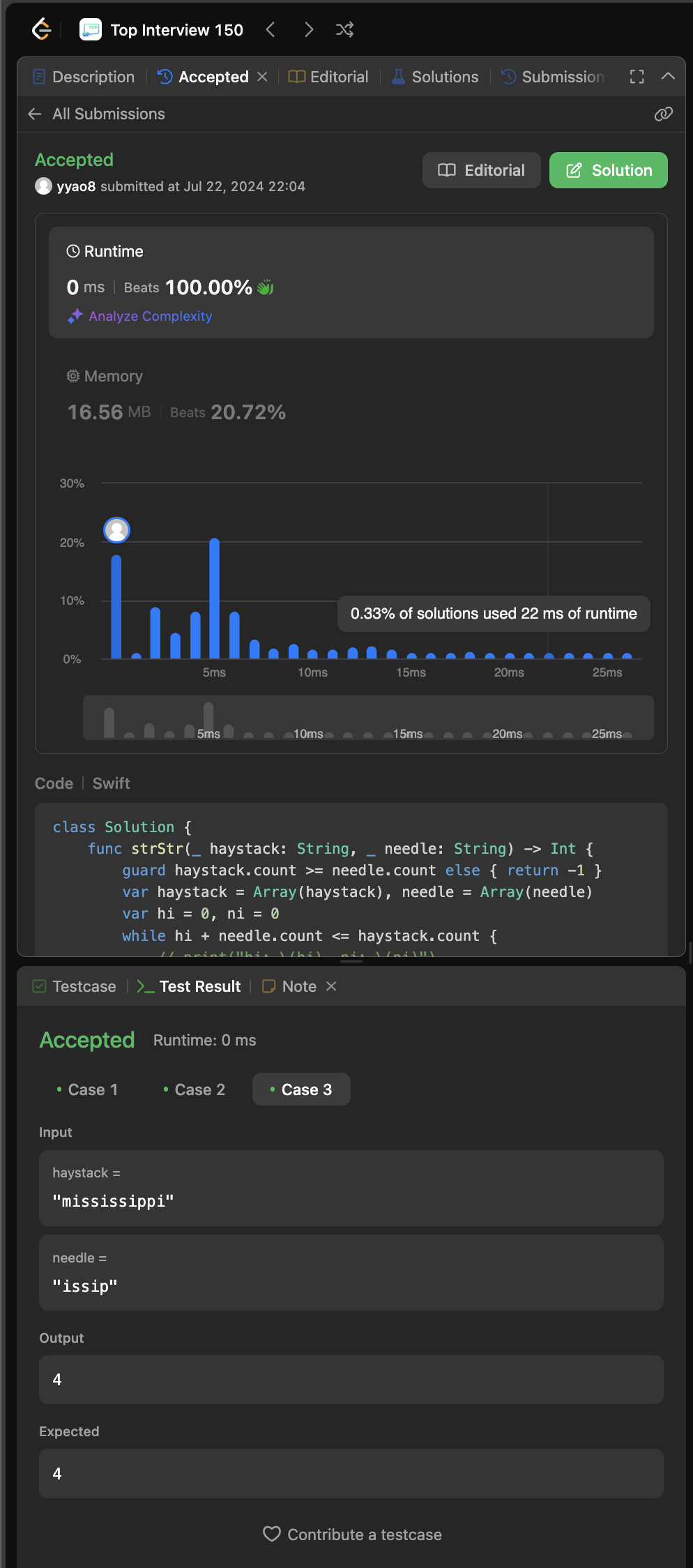
28. Find the index of the first ocurence in a string
Problem description
Given two strings needle and haystack, return the index of the first occurrence of needle in haystack, or -1 if needle is not part of haystack.
Example 1:
Input: haystack = “sadbutsad”, needle = “sad”
Output: 0
Explanation: “sad” occurs at index 0 and 6.
The first occurrence is at index 0, so we return 0.
Example 2:
Input: haystack = “leetcode”, needle = “leeto”
Output: -1
Explanation: “leeto” did not occur in “leetcode”, so we return -1.
Constraints:
1 <= haystack.length, needle.length <= 104
haystack and needle consist of only lowercase English characters.
KMP Algorithm
KMP working analysis
Take this as an example:
1 | let s1 = "ABCDAB ABCDABCDABDE" |
A brute force solution would be to compare each character of s1 with s2 and if a mismatch is found, we start comparing from the next character of s1 with the start of s2. This will be inefficient as we are not utilizing the information that we already know in previous loops. i.e. from the example above, we have walked through the first 6 characters of s1 before we reach the last D in s2, which is the mismatch, 7th character of both, so the next position we should comare with s2‘s first character is not the 2nd character of s1 because we know the 2nd character of s1 is B and B is not equal to A.
We should instead skip as many characters as possible to avoid unnecessary comparisons. How do we do that? We need to build a table that tells us how many characters we can skip when a mismatch is found. That table will tell us that we should jump to the 5th character of s1 to continue the compare because we know the last two characters of s1 are AB and AB is equal to AB in s2, which is the first two characters of s2, which means we can possibly find a match from the 5th character of s1 (but not guaranteed, still need to compare all the rest characters of s2 with s1).
此时回溯时,A 还会去和 BCD 进行比较,而在上一步 ABCDAB 与 ABCDABD,前 6 个都相等,其中 BCD 搜索词的第一个字符 A 不相等,那么这个时候还要用 A 去匹配 BCD,这肯定会匹配失败。
KMP 算法的想法是:设法利用这个已知信息,不要把「搜索位置」移回已经比较过的位置,继续把它向后移,这样就提高了效率。
那么新的问题就来了:你如何知道 A 与 BCD 不相同,并且只有 BCD 不用比较呢?这个就是 KMP 的核心原理了。
KMP 利用 部分匹配表,来省略掉刚刚重复的步骤。
匹配表应该告诉我们:
ABCD 匹配值 0
ABCDA 匹配值 1
ABCDAB 匹配值 2
已知空格与 D 不匹配时,前面 6 个字符 ABCDAB 是匹配的。
查表可知:部分匹配值是 2,因此按照下面的公司计算出后移的位数:
移动位数 = 已匹配的字符数 - 对应的部分匹配值
4 = 6 - 2
因此回溯的时候往后移动 4 位,而不是暴力匹配移动的 1 位。
How to build the table
The table is expected to tell us the partial match value of the substring. The partial match value is the length of the longest proper prefix of the substring that is also a proper suffix of the substring.
The following table shows the partial match value of the substring ABCDABD:
Note the prefix should exclude the last character of the substring and the suffix should exclude the first character of the substring.
| Substring | Prefix | Suffix | Common Prefix and Suffix | Partial Match Value |
|---|---|---|---|---|
| A | - | - | - | 0 |
| AB | A | B | - | 0 |
| ABC | A, AB | BC, C | - | 0 |
| ABCD | A, AB, ABC | BCD, CD, D | - | 0 |
| ABCDA | A, AB, ABC, ABCD | BCDA, CDA, DA, A | A | 1 |
| ABCDAB | A, AB, ABC, ABCD, ABCDA | BCDAB, CDAB, DAB, AB, B | AB | 2 |
Implementation steps
- Build the table
- Use the table to complete the KMP matching algorithm
Build the table
1 | extension String { |
Use the table
1 | class Solution { |
Leetcode submission result